Python: Pandas
pandas is a Python package providing data frames - fast, flexible, and expressive data structure designed to make working with tabular data both easy and intuitive. It is one of the key pieces in the Python data science toolkit!
pandas is well suited for many different kinds of data [1]:
- Tabular data with heterogeneously-typed columns, as in an SQL table or Excel spreadsheet
- Ordered and unordered (not necessarily fixed-frequency) time series data.
- Arbitrary matrix data (homogeneously typed or heterogeneous) with row and column labels
- Any other form of observational / statistical data sets. The data actually need not be labeled at all to be placed into a pandas data structure
Please watch the following video to learn more about pandas.
Today's learning objectives
- Understand what a
pandasdataframe entails - Load, edit, and save common file formats using Python Pandas.
Installing Pandas
The simplest way to install not only pandas, but Python and the most popular packages that make up the SciPy stack is with Anaconda, which you have already installed.
Dataframes
A pandas dataframe is a data structure that can be best understood as a list of lists. A data frame is a matrix of data, containing rows and columns,and ideally the first row contains the header - the name of each column.
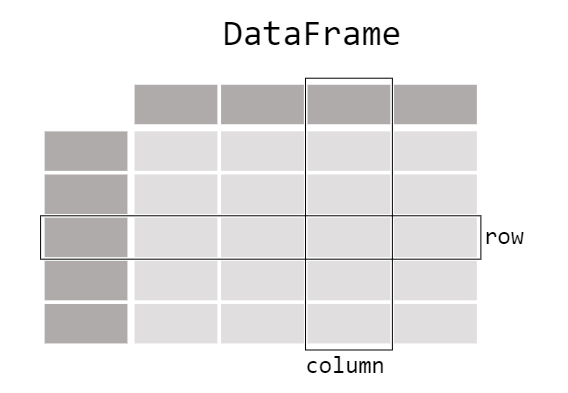
Please watch the following video to learn more about dataframes in pandas.
Blended Learning - Code Academy - Pandas [4 hrs]
- Please complete the
Learn Data Analysis with Pandasmodule in Code Academy which can be found here.
References
[1] https://pandas.pydata.org/docs/getting_started/install.html
[2] https://www.codecademy.com/learn/data-processing-pandas
Please click next to view the rest of the material for today