Clustering: K-Means
We start with a introduction to clustering. We will then continue with the workshop, which covers a commonly used clustering algorithm - the k-means algorithm. The workshop will consist of some interactive lessons, two short quizzes and a mini-project.
0) Learning Objectives:
After this module you'll know the fundamental theory on, and how to:
- Understand and apply a clustering algorithm.
Table of contents:
- Introduction to concepts: 0.5 hours
- Workshop: 7 hours
Questions or issues?
If you have any questions or issues regarding the course material, please first ask your peers or ask us in the Q&A in Datalab!
Good luck!
1) Introduction
Clustering algorithms (or cluster analysis) aim to group data points into clusters such that data points within a cluster are more closely related to one another than data points assigned to different clusters.
Suppose we are given a dataset with the following data points:
The goal of clustering algorithm is to automatically find stucture in the data, that allows us to infer groups of data points that are in some way similar, althought note the groups need not always correspond to real-life categories.
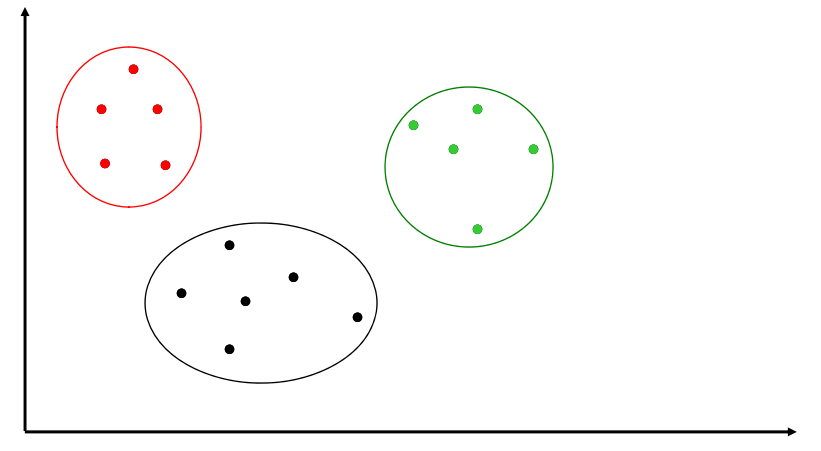
Examples of clustering applications are:
- Recommendation engines: netflix grouping movies based on genre
- Search engines: group search results based on topic (e.g., news)
- Market segmentation: group customers based on geography, demography, and behaviors
- Image segmentation: group medical X-rays images into OK (no disease) and NOK (possible disease)
Please watch the following video to get an insight into clustering analyses.
As discussed in the above video, clustering is an example of Unsupervised Learning, as we do not provide the algorithm with explicit labels. The algorithm automatically looks for underlying features in the dataset which lead to clusters which are similar.
2) Workshop
Now, we're introduced to Cluster analysis it's time ground down these fundamental by doing a workshop on the KMeans algorithm. Open the Basics of Machine Learning course on Codecademy and complete the module: Clustering: K-Means, in particular:
- Lesson: K-Means Clustering
- Quiz: K-Means Clustering
- Lesson: K-Means++ Clustering
You will have time to work on the Handwriting Recognition using K-Means project tomorrow in the data lab.
Next up!
Coming Datalab we will reflect on K-means Clustering Analyses again and give you an opportunity to ask any questions you might have.
In datalab, we will apply K-means clustering on our problem statement for the Oosterhout dataset!