Decision Trees
We start with a introduction to tree based analysis, and in particular decision trees. We will then continue with the workshop, which consists of some interactive lessons, two short quizzes and a mini-project.
0) Learning Objectives:
After this module you'll know the fundamental theory on, and how to:
- Understand and apply a decision tree algorithm.
Table of contents:
- Introduction to concepts: 0.5 hours
- Workshop: 5 hours
- Quiz: 0.5 hours
- Project: 1 hour
Questions or issues?
If you have any questions or issues regarding the course material, please first ask your peers or ask us in the Q&A in Datalab!
Good luck!
1) Introduction
A decision tree is an example of a supervised learning algorithm that can be either used for regression or clasification. In some cases, you may come across the terms regression trees, and classification trees - which are nothing but decision tree algorithms for regression and classification respectively. In this module, we will focus on classification trees.
Similar to a flowchart, which represents the flow of decision making logic in a computer program, a decision tres uses a tree structure to represent the decision rules learned from data.
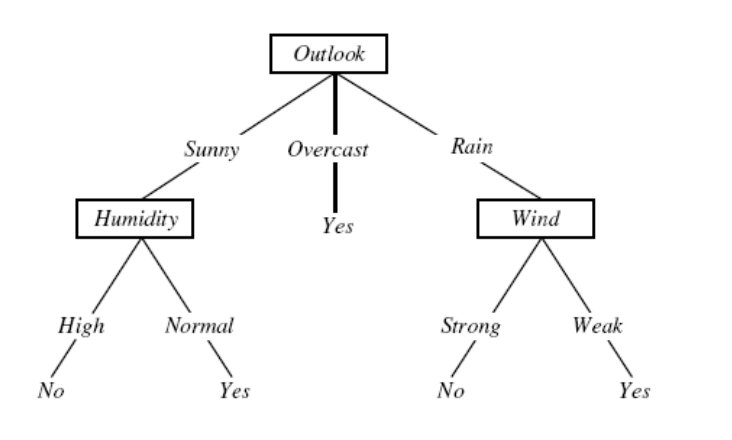
In the above tree, each node represents a feature (e.g., Outlook) in the dataset, and the differnt possible outcomes for each feature (e.g., Sunny, Overcast, Rain) lead to new branches in the tree. The final nodes are leaf nodes which represent the class (or target) labels.
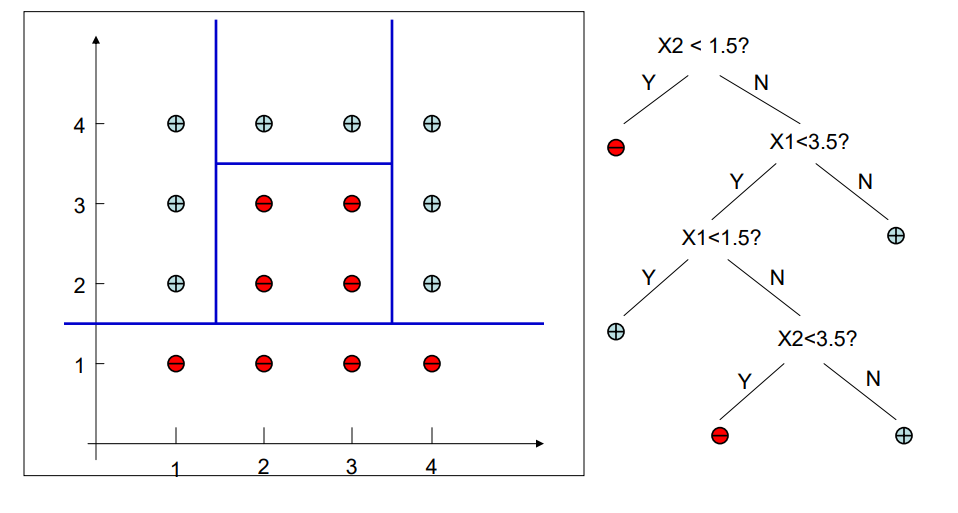
Similar to the KNN classification algorithm, the decision tree also relies on creating decision boundaries to decide if a given point belongs to a particular class or not. However, unlike KNN, decision trees create explicit decision rules that can be stored and retrieved at a later point to predict the class of a new data point.
In the following workshop on CodeAcademy, you will learn how to explicity create such decision rules, and further, how to apply such algorithms using scikit-learn.
2) Workshop
Now, we're introduced to tree-based analyses, it's time ground down these fundamental by doing a workshop. Open the Basics of Machine Learning course on Codecademy and complete half of the modules: Decision Trees, specifically complete:
- Lesson: Decision Trees
- Quiz: Decision Trees
- Project: Find the Flag
If you find yourself stuck in the project, please click here
3) Q&A
Coming Datalab we will reflect on tree-based analysis again and give you an opportunity to ask any questions you might have.
Up Next!
Tomorrow we will cover Random Forests!